Abstract
Detection-based methods have been viewed unfavorably in crowd analysis for their poor performance in dense crowds. However, we argue that their potential has been underestimated as some crucial information for crowd analysis is inherent in the detection pipeline while never utilized. In particular, the area size and confidence score of output proposals and bounding boxes indicate the scale and density of the crowd. Thus, we propose a Crowd Hat structure on top of detection to leverage these underutilized output features. Specifically, we first introduce a mixed 2D-1D compression to refine output features and obtain the spatial and numerical distribution of these crowd-specific information. Based on these features, we further propose region-adaptive NMS thresholds and a decouple-then-align paradigm that successfully addresses drawbacks in detection-based methods. We conduct extensive evaluations on various crowd analysis tasks of crowd counting, localization, and detection, showing our approach can be easily adapted to different detection methods while achieving state-of-the-art performance.
Output Features
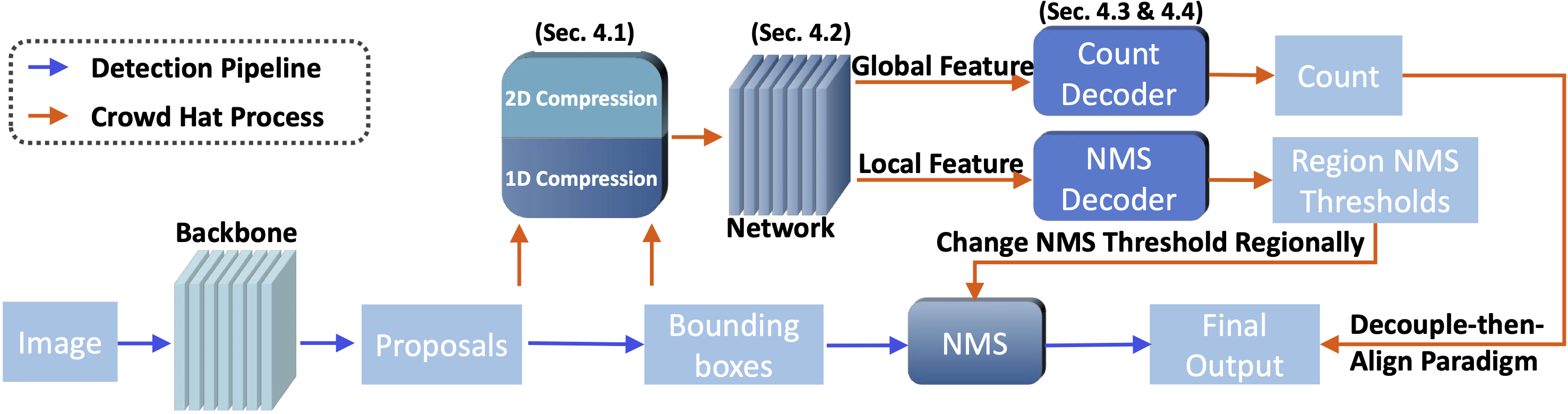
In our paper, we define detection outputs as the predicted bounding boxes and proposals from the detection network. We find these outputs convey abundant crowd-specific information, making them valuable assets for crowd analysis tasks. In particular, we adopt two output features "area size" and "confidence score" from detection outputs. Compared to feature maps extracted from convolution layers (CNN features), output features focus mostly on humans, the foreground of the image, which are considered relatively "pure" features for crowd analysis tasks. We show visualizations of these features below.
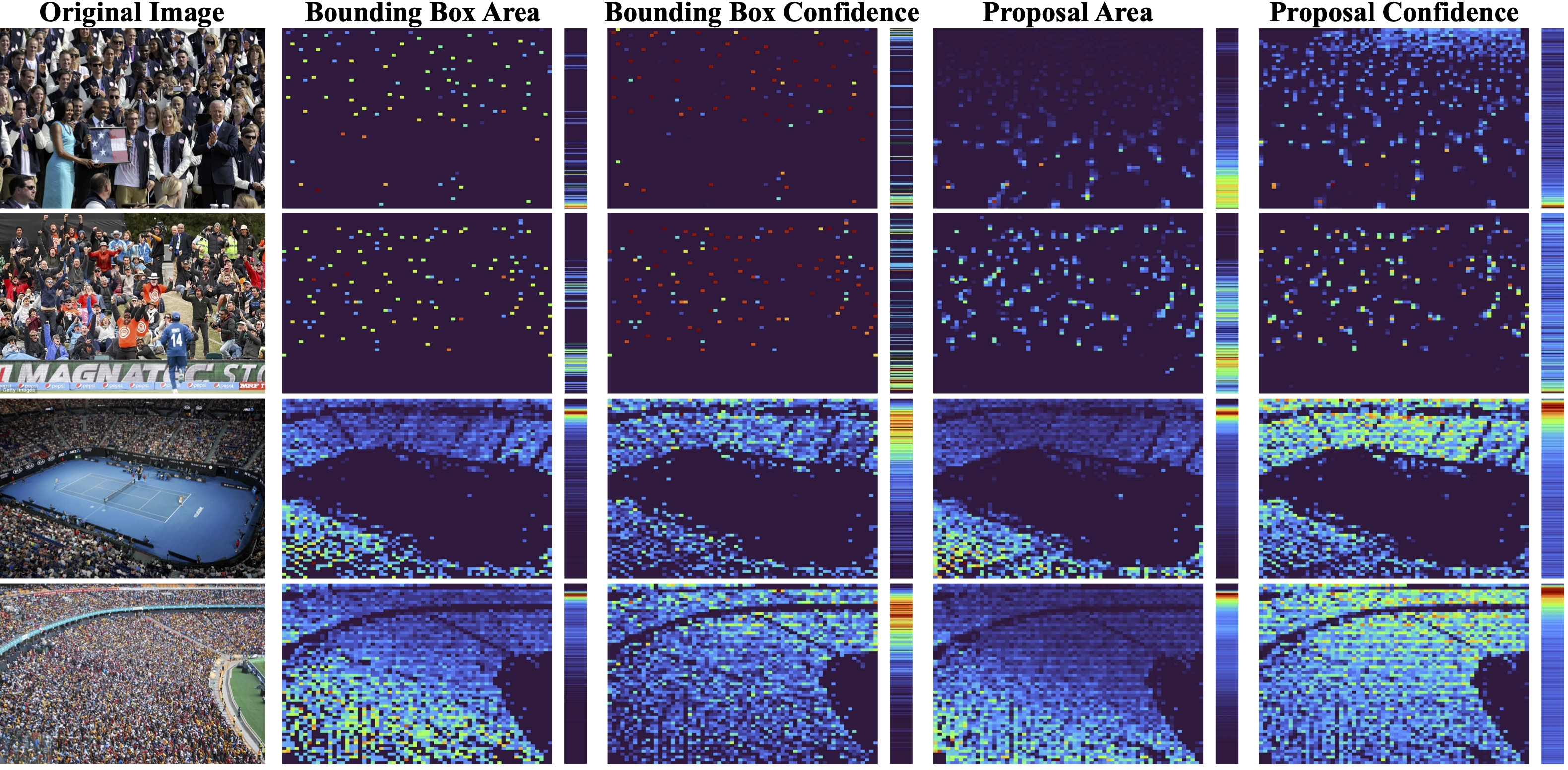
Pipeline
We first introduce a mixed 2D-1D compression to refine both spatial and numerical distribution of output features from the detection pipeline. To make use of these features, we then propose a NMS decoder to learn region-adaptive NMS thresholds, which effectively reduces a large number of false positives under low-density regions and false negatives under high-density regions. Furthermore, we introduce a decouple-then-align paradigm to improve counting performance by first directly regressing the crowd count from output features and then use this predicted count to guide the bounding box selection.